The Spread of Mass Surveillance, 1995 to Present
ICYMI (In Case You Missed It), the following work was presented at the 2017 Annual Meeting of the American Political Science Association (APSA). The presentation, titled “Big Data Innovation Transfer and Governance in Emerging High Technology States” was a part of the session “The Role of Business in Information Technology and Politics” on Friday September 1, 2017.
Post developed by Nadiya Kostyuk and Muzammil M. Hussain
On August 24, 2017, India’s highest court ruled that citizens have a fundamental right to privacy. Such a ruling may serve to slowdown the government’s deployment of the Aadhaar national ID program, a robust relational database connecting each of India’s 1.3+ billion citizens with their unique 12-digit identity aimed at centralize their physiological, demographic, and digital data shadows — minute pieces of data created when an individual sends an email, updates a social media profile, swipes a credit card, uses an ATM, etc. While the government has presented the Aadhaar system as an improved channel to provide social security benefits for its nationals, India’s civil society organizations have protested it as a means of furthering government surveillance. India’s trajectory in ambitiously modernizing its high-tech toolkit for governance represents a rapidly spreading trend in the contemporary world system of 190+ nations.
Take China as an other example. China has recently mobilized its government bureaucracies to establish the worlds’ first ever, and largest, national Social Credit System covering nearly 1.4+ billion Chinese citizens. By 2020, China’s citizen management system will include each Chinese national’s financial history, online comments about government, and even traffic violations to rank their ‘trustworthiness.’ Like India’s, these unique ‘social credit’ ratings will reward and punish citizens for their behavioral allegiance with the regime’s goals by scientifically allowing the state to operationalize its vision of a “harmonious socialist society.”
Yet, the implementation of state-sponsored and ‘big data’-enabled surveillance systems to address the operational demands of governance is not limited just to the world’s largest democratic and authoritarian states. This summer, at the annual meetings of the International Communication Association (May 2017, San Diego) and the American Political Science Association (August 2017, San Francisco), the project on Big Data Innovation & Governance (BigDIG) presented findings from the first event-catalogued case-history analysis of 306 cases of mass surveillance systems that currently exist across 139 nation-states in the world system (Kostyuk, Chen, Das, Liang and Hussain, 2017). After identifying the ‘known universe’ of these population-wide data infrastructures that now shape the evolving relationships between citizens and state powers, our investigation paid particular attention to how state-sponsored mass surveillance systems have spread through the world-system, since 1995.
By closely investigating all known cases of state-backed cross-sector surveillance collaborations, our findings demonstrate that the deployment of mass surveillance systems by states has been globally increasing throughout the last twenty years (Figure 1). More importantly, from 2006-2010 to present, states have uniformly doubled their surveillance investments compared with the previous decade.
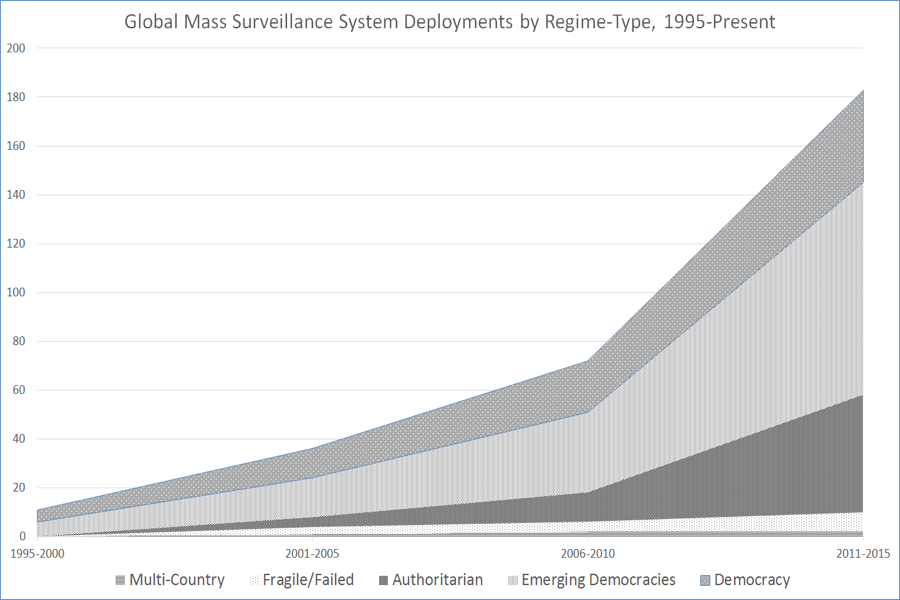
In addition to unpacking the funding and diffusion of mass surveillance systems, we are also addressing the following questions: Which stakeholders have most prominently expressed support for, benefited from, or opposed these systems, and why? What have been the comparative societal responses to the normalization of these systems for the purposes of population management in recent decades?
The observed cases in our study differ in scope and impact.

Why do stable democracies and autocracies operate similarly, while developing and emerging democracies operate differently? Access to and organization of material, financial, and technocratic resources may provide some context.
While nations worldwide have spent at least $27.1 billion USD (or $7 per individual) to surveil 4.138 billion individuals (i.e., 73 percent of the world population), stable autocracies are the highest per-capita spenders on mass surveillance. In total, authoritarian regimes have spent $10.967 billion USD to surveil 81 percent of their populations (0.1 billion individuals), even though this sub-set of states tends to have the lowest levels of high-technology capabilities. Stable autocracies have also invested 11-fold more than any other regime-type, by spending $110 USD per individual surveilled, followed second-highest by advanced democracies who have invested $8.909 billion USD in total ($11 USD per individual) covering 0.812 billion individuals (74 percent of their population). In contrast to high-spending dictatorships and democracies, developing and emerging democracies have invested $4.784 billion USD (or $1-2 per individual) for tracking 2.875 billion people (72 percent of their population).
It is possible that in a hyper-globalizing environment increasingly characterized by non-state economic (e.g., multi-national corporations) and political (e.g., transnational terror organizations) activity, nation-states have both learned from and mimicked each other’s investments in mass surveillance as an increasingly central activity in exercising power over their polities and jurisdictions. It is also likely that the technological revolution in digitally-enabled big data and cloud computing capabilities as well as the ubiquitous digital wiring of global populations (through mobile telephony and digital communication) have technically enabled states to access and organize population-wide data on their citizens in ways not possible in previous eras. Regardless of the impetuses for increases in mass surveillance efforts, our research aims to provide empirical support to advance theory and guide policy on balancing security needs and privacy concerns at a time where many governments are ambitiously upgrading their governance systems with unbridled hi-tech capabilities.