Citizens in a democracy must have access to reliable information about what is happening in government policy in order to form meaningful preferences and hold politicians accountable. But do media consumers get the information they need to have informed policy preferences?
Past research suggests that public opinion on policy issues is thermostatic; that is, the public adjust their preferences for policy spending downward when spending increases and upward when spending decreases. In their new book, Information and Democracy: Public Policy in the News, Stuart Soroka and Christopher Wlezien argue that the public respond in this way because they are getting information about policy spending from the news.
For anyone paying attention to academic or public debates about news quality, it may not seem like this could be the case. Consider that the news media are regularly accused of having a partisan bias, failing to cover important issues, or relying on sensationalism to draw in viewers. Moreover, researchers and other observers also have concerns about the ability of the public to process the information they do receive; many people are not interested in following the news, and those that do may interpret information through a lens of pre-existing beliefs.
Nevertheless, the public does seem to be picking up on cues about policy. Soroka and Wlezien set out to measure the accuracy of media coverage of policy and identify the domains where the media tend to provide more or less faithful coverage of policy. In the book, they investigate the frequency and reliability of media coverage in five spending domains: defense, welfare, health, education, and the environment. Examining decades of government spending, media coverage, and public opinion in the US, Information and Democracy assesses the accuracy of media coverage, and assesses its direct impact on citizens’ preferences for policy.
To measure media accuracy, the authors use a two-step process. First, they create a “media policy signal” which is based on using a dictionary to code sentences about spending in each of the five policy domains across different news outlets. The dictionary codes each sentence as positive/upward changes in spending, negative/downward changes in spending, or no change in spending, scored +1, -1, or 0, respectively. The “media policy signal” is a sum of these codes by year, so that years where there are more upward changes in spending, the signal is positive, and years in which there are more downward changes, the signal is negative. The second step involves modeling the “media policy signal” against actual changes in the budget for these policy domains over time. Actual changes in the budget are drawn from the Historical Tables released by the Office of Management and Budget (OMB).
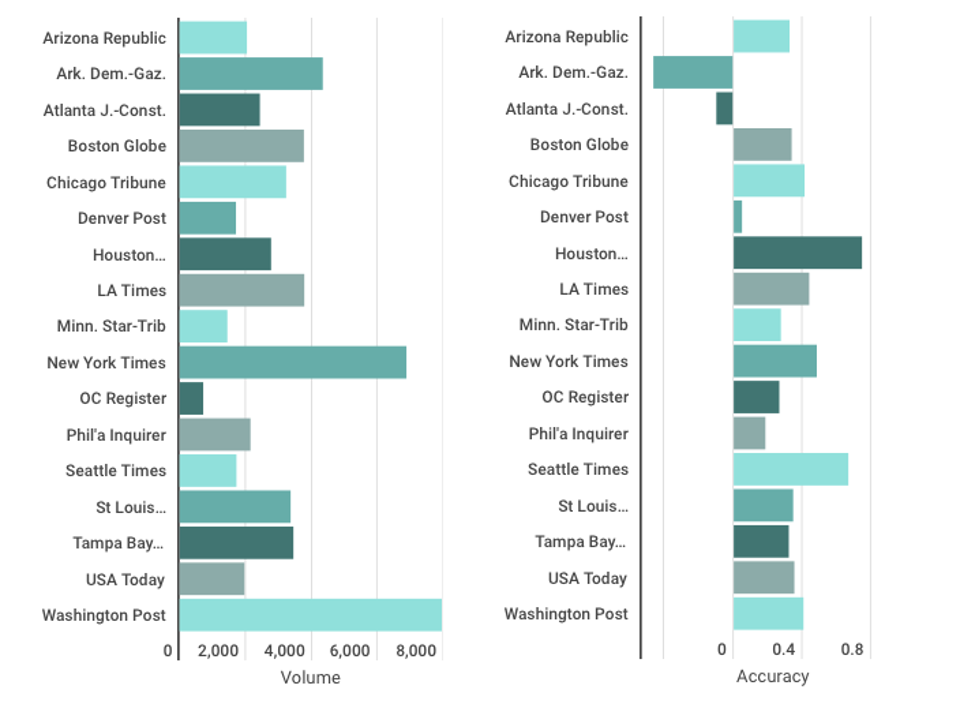
A website based on the book is available at http://mediaaccuracy.net, where users can examine both the volume and accuracy of media coverage of policy by news outlet across the five topic domains. These volume and accuracy measures are based on the method described above and cover the computer-automated content analyses of millions of newspaper articles and television transcripts. Data displayed on the website compare the “signal” in media coverage to actual budgetary policy change. When media coverage matches policy change, media accuracy is high. When media coverage does not match policy change, media accuracy is low. Through a series of infographics, readers can examine the accuracy of 17 major US newspapers and 6 television networks over the past 20-30 years.
The results show a more nuanced picture of the relationship between media coverage and actual spending on policy than critics might expect. In some domains, news coverage indeed does not reflect changes in spending especially well. However, there are other domains, such as defense, welfare, and health where the relationship between news coverage and actual spending is strong. http://mediaaccuracy.net shows how this extends to individual news outlets. These results suggest that, while not always accurate, the media can convey accurate and useful information about government spending, and can play a role in the political accountability necessary in a modern democracy. The degree to which this is true does vary across outlets, however, sometimes in substantial ways.
Newspaper coverage of welfare
The chart above shows volume and accuracy scores for newspaper coverage of welfare, with media outlets in alphabetical order.
Post developed by Anne Pitcher, Rod Alence, Melanie Roberts, and Katherine Pearson
Secure elections are essential to democracy. ObSERV, a new study by researchers at the Electoral Institute for Sustainable Democracy in Africa (EISA) and the University of Michigan, with support from the University of Witwatersrand (Wits), presents a data collection methodology that improves the placement of election observers in order to improve the quality of their observations regarding the electoral process.
Election Observation Missions (EOM) seek to provide impartial observation of the electoral process in order to ensure the peaceful conduct of elections and to protect the rights of citizens to participate and to vote. On the African continent, however, the deployment of observers has been driven more by practical convenience than by a representative and systematic approach to deployment. Deploying observers just taking convenience into consideration potentially results in the collection of information from observers that is biased or misleading. Subsequently, this information can influence the content and tone of election reports that EOMs issue regarding the extent to which elections are “free” and “fair”.
Observer data that is collected more systematically and is geographically referenced provides a more accurate and representative description of an election. Such data can also be linked more fruitfully to other sources of contextual information – from local demographics and infrastructure to partisan polarization and the prevalence of political violence. ObSERV’s approach to deploying observers not only supports the goal of assessing how free and fair the current election is, it also enables researchers to analyze and better understand the causes of deeper threats to democracy, such as election-related violence and electoral fraud.
How does ObSERV work?
ObSERV uses computer algorithms to group polling stations into local clusters and then to draw a random sample of clusters to be visited by observer teams. Stations are clustered to minimize driving distance for each team, which must cover at least 12 stations on election day, using routing tools similar to those used by modern carpooling apps. Clusters are then categorized between regions and urban and rural locations, and the required number of clusters is selected randomly within each category.
Clusters are subjected to a security assessment, to ensure that observers can safely access them. Where the security assessment (commissioned by the observer mission itself) identifies safety concerns with a cluster, it is removed and a substitute is drawn using the ObSERV method. Once in the field, observers use EISA’s Popola monitoring system to report on a range of election-related activities, from rallies to voting. The information captured helps the mission evaluate the overall conduct of the election, and a substantial part of it is curated for inclusion in the ObSERV data set.
The value of ObSERV
By collecting observer data systematically and attaching geographical coordinates, ObSERV facilitates linking to other data sets relevant for analyzing and better understanding localized patterns of election-related violence. Applications are not limited to issues of electoral security and violence. The data collected also include station-level details such as long voter queues, missing materials, voters being turned away, and voters showing up at the wrong station.
ObSERV’s approach can be adapted for anywhere observation takes place, as it accommodates the practical challenges of deploying an observer mission. By applying systematic methods, observers end up observing polling stations that have previously been overlooked, improving the quality of election observation. Over time, use of the ObSERV method will contribute to a cumulative body of research data, promoting better understanding and analysis of African elections and ultimately help protect the integrity of the democratic process.
For the past two years, a team of data science experts have been experimenting with offering expert office hours to facilitate the adoption of new methods and technologies across the Institute for Social Research (ISR). These CoderSpaces provide immediate research support and offer hands-on learning opportunities for participants who wish to grow their coding and data science skills. The aim is to foster a casual learning and consulting environment that welcomes everyone regardless of skill level.
CoderSpaces are one way to help researchers thrive in an environment that is becoming increasingly complex. With the ongoing digitization of our daily lives, scholars are gaining access to new types of data streams that have not been traditionally available in their disciplines. For example, social scientists in the ISR at the University of Michigan have started to explore the ways in which virtual interactions on social media platforms can inform the scientific inquiry of socio-behavioral phenomena spanning many aspects of our lives, including election forensics, political communication, parenting, or insights gained from survey research.
Processing and analyzing novel types and ever bigger quantities of data requires that faculty, research staff, and students incorporate new research technologies and methodologies in their scientific toolkits. For example, researchers may need to move computationally intense analyses to a high performance computing cluster, which requires familiarity with batch processing, a command line interface, and advanced data storage solutions. Or researchers may be confronted with understanding and implementing natural language processing and machine learning to systematically retrieve information from large amounts of unstructured text.
Researchers who embark on the journey of exploring new technologies or methodology often can not fall back on curricula and training opportunities provided by their disciplinary peers. The relevant learning resources still need to be developed – potentially by themselves one day. To bridge training gaps, scholars look to example applications in other disciplines, engage in interdisciplinary research collaborations to access necessary expertise, and solicit help from available support units on campus to make methodological and technological innovations possible.
CoderSpaces provide just this kind of support. The sessions are hosted by faculty, research staff, and students who are willing to share their methodological and programming expertise with others. Initially, CoderSpaces were limited to the ISR community. Currently, anyone at the University of Michigan is welcomed to join, which has allowed us to diversify and broaden the available expertise and research applications. The weekly sessions were originally organized as in-person gatherings at the ISR with the intent to venture out to other campus locations. In March 2020, CoderSpaces moved to a virtual format facilitated by Zoom video-conferencing and a Slack communication space. Going virtual turned out to be a blessing in disguise as it enabled anyone at the university to participate regardless of their physical location, helping us broaden our reach across U-M departments and disciplines.
We have continuously increased the number of our CoderSpaces hosts over time. The current Winter 2021 team is our largest and most diverse yet, with 16 hosts representing nine campus departments that span the social and medical sciences, technical and statistical fields. The expertise we are able to provide ranges from high performance and parallel computing, cloud analytics, performance analysis, statistical modelling and machine learning, survey methods, natural language processing, research design, reproducible workflows, data management, programming in a variety of languages (bash, C, C++, C#, CMake/GNU Make, Fortran, Java, Javascript, Julia, LaTeX, Matlab, Markdown, Perl, Python, R, Rcpp, SAS, shell, Slurm, SQL, Stata), version control in Git, mobile app development, web scraping, and more. Typically, we are able to assist participants with their issues immediately during the virtual meeting. If a solution is not readily available, our hosts draw on their respective expertise and network to identify additional resources and offer support.
Participants join an ongoing Zoom meeting at the scheduled weekly times. The hosts on the call field questions and may use the breakout room feature to assist multiple participants simultaneously. For example, Bryan Kinzer, a PhD student in Mechanical Engineering, attended CoderSpaces a few times to set up and run a Singularity container. He says of his experience: “The hosts were helpful and patient. My issue was not a super easy quick fix, but they were able to point me in the right direction eventually getting the issue resolved. When I came back the following week they remembered my case and were able to pick right back up where I left off.”
Paul Schulz, a senior consulting statistician and data scientist for ISR’s Population Dynamics and Health Program (PDHP), has now been serving as a host since the CoderSpaces were launched. He describes the weekly CoderSpaces as “an enriching experience that has allowed me and the other PDHP staff members to socialize and broaden our network among other people on campus who work in the data and technical space. By sharing our technical skills and knowledge with attendees, we are providing a service. But we have also been able to improve our own skills and expertise in these areas by being exposed to what others across campus are doing. By fostering these types of informal collaborations and shared experiences, I think that the CoderSpaces have been a win-win for both attendees and hosts alike.”
Post developed by Nicholas Valentino and Katherine Pearson
Survey research is an ever-evolving field. Technology has increased the number of ways to reach respondents, while simultaneously reducing response rates by freeing people from the constraints of one land-line telephone per household. Surveys remain an essential tool for making inferences about societal and political trends, so many survey researchers offer incentives to survey respondents in order to ensure a large and representative sample. Financial incentives to complete surveys, in turn, entice some people to respond to a large number of online surveys on a regular basis, essentially becoming professional survey respondents.
Survey methodologists have carefully considered the ways that survey modes may impact the way people answer questions. Talking to a real person is different than answering questions online. But less is known about how individual factors bias participation in surveys in the first place. For example, might personality traits shape your willingness to agree to answer a survey online versus someone who comes to your door? New work from researchers at the University of Michigan and Duke suggests in fact this is the case.
In order to examine the personality traits of survey respondents, the research team used data from the 2012 and 2016 American National Election Studies (ANES). During these two study periods, the ANES ran parallel and face-to-face surveys. In both years, the ANES included the 10-item personality inventory (TIPI), which consists of pairs of items asking respondents to assess their own traits. Based on the responses, respondents build a profile of “the Big Five” personality traits: openness to experience, conscientiousness, extraversion, agreeableness, and emotional stability.
Big Five traits with corresponding TIPI qualities
Trait
TIPI Qualities
Coding
Openness to experience
Open to new experiences, complex
Conventional, uncreative
Original
Reversed
Conscientiousness
Dependable, self-disciplined
Disorganized, careless
Original
Reversed
Extraversion
Extraverted, enthusiastic
Reserved, quiet
Original
Reversed
Agreeableness
Critical, quarrelsome
Sympathetic, warm
Reversed
Original
Emotional Stability
Anxious, easily upset
Calm, emotionally stable
Reversed
Original
Researchers were able to compare responses to the TIPI with measures of political predispositions and policy preferences, based on responses to questions on the ANES. These include partisanship, liberal–conservative ideology, issue self-placements, and other measures of political orientation.
Based on these data, the authors found that respondents in the online samples were, on average, less open to experience and more politically conservative on a variety of issues compared to those responding to face-to-face surveys. They also found that the more surveys a respondent completed, the lower they scored on measures of openness. Given that professionalized survey respondents comprise the majority of online survey samples, these results suggest caution for those who would like to generalize results to the population at large. It is not enough to balance samples on simple demographics. Attitudinal and personality based differences might also lead online sample estimates to diverge from the truth.
It is difficult to say whether online survey respondents or face-to-face respondents are more representative of personality traits in the general population. If personality is a factor in whether someone will participate in a survey, that might bias both types of samples. However, the authors note that the data suggest that professional online samples are the outlier. They find “that samples based on fresh cross-sections, both face-to-face and online, yield better population estimates for personality and political attitudes compared to professionalized panels.” While it may be possible to mitigate the potential sampling bias of personality traits, it is important that survey researchers understand the role that personality traits play in professional online samples.
In every U.S. presidential election since 1948, the American National Election Studies (ANES) has conducted pre- and post-election surveys of a large representative sample of American voters. ANES participant interviews looked different in 2020 than they did in the past; the COVID19 pandemic made traditional face-to-face interviews impractical and risky. The study team began planning for the extraordinary circumstances in March, without any idea what the conditions would be when interviews began in August. The team pivoted nimbly to redesign the study even as the onset of data collection approached.
The majority of interviews in 2020 were completed as web surveys, some following an online format similar to one used in 2016, and others using an innovative mixed-mode design. Respondents to the mixed-mode surveys were randomly assigned either to complete the questionnaire by themselves online, or to take the survey with a live interviewer via a Zoom video link. Few surveys conduct live video interviews, but the ANES study team felt that it was critical to explore the use of this technology as a potential means of balancing issues of cost, continuity, and data quality.
To answer online surveys, respondents must have reliable access to the Internet and comfort using computers. Under normal circumstances, people without access to computers or the Internet in their homes can gain access in public settings like libraries or at their workplace. With many of these places closed due to the pandemic, online access became a bigger challenge. In mixed-mode cases where it was difficult to complete a web or video interview, interviewers contacted the respondents to secure a phone interview. Providing phone interviews helped the team strengthen sample quality by reaching respondents without access to the Internet as well as those who are less comfortable using computers.
Data collection for the 2020 surveys, out of necessity, departed significantly from the practices of the past 70 years of the ANES. The study team will continue to monitor and address the implications of these changes. In the end, the team was pleased to field a very high quality survey with relatively high response rates, thoroughly vetted questions, and the largest sample in the history of ANES.
Pre-election surveys
Pre-election interviews began in August 2020. The pre-election questionnaire is available on the ANES website. The questionnaire includes time series questions dating back to the earliest days of the ANES survey, as well as new questions that reflect more recent developments in the study of American politics. The ANES team must always be prepared to add a few questions late in the design process to capture substantial developments in the presidential campaign or American society. In 2020 the survey added questions about election integrity, urban unrest, and COVID-19, among other topics.
The investigators, ANES staff, and their survey operations partners at Westat monitored the data collection closely, in case further adjustments in procedures or sample were required. The final pre-election sample consists of over 8,200 complete or sufficient-partial interviews. This includes a reinterview panel with the respondents from the ANES 2016 Time Series. Over 2,800 respondents from the 2016 study were reinterviewed, more than three quarters of the original group.
Post-election surveys
Post-election interviews began on November 8, 2020, and will be completed on January 4, 2021. This post-election effort includes additional respondents who took part in the 2000 study of the General Social Survey (GSS). Due to the pandemic-altered timing of the GSS data collection, it was not possible to interview these individuals prior to the election. However, these respondents completed nearly all of the ANES post-election interview, plus almost ten minutes of critical questions that appeared on the ANES pre-election interview, and several additional questions suggested by the GSS team.
ANES staff will continue to review and clean the data into the new year, including checks of respondent eligibility that may alter the final sample in modest ways. Pending this review, the team expects response rates to come in slightly below the 2016 web response rates.
Overall, despite the challenges of this past year, the ANES study team was able to gather robust data from a large probability sample of Americans, extending the longest-running, most in-depth, and highest quality survey of US public opinion and voting behavior, at a critical juncture for American society and democracy. The team will continue to share updates, here and on the ANES website, as data from this survey become available.
Political science has been enriched by the use of social media data. However, automated text-based classification systems often do not capture image content. Since images provide rich context and information in many tweets, these classifiers do not capture the full meaning of the tweet. In a new paper presented at the 2020 Annual Meeting of the American Political Science Association (APSA), Patrick Wu, Alejandro Pineda, and Walter Mebane propose a new approach for analyzing Twitter data using a joint image-text classifier.
Human coders of social media data are able to observe both the text of a tweet and an attached image to determine the full meaning of an election incident being described. For example, the authors show the image and tweet below.
If only the text is considered, “Early voting lines in Palm Beach County, Florida #iReport #vote #Florida @CNN”, a reader would not be able to tell that the line was long. Conversely, if the image is considered separately from the text, the viewer would not know that it pictured a polling place. It’s only when the text and image are combined that the message becomes clear.
MARMOT
A new framework called Multimodal Representations Using Modality Translation (MARMOT) is designed to improve data labeling for research on social media content. MARMOT uses modality translation to generate captions of the images in the data, then uses a model to learn the patterns between the text features, the image caption features, and the image features. This is an important methodological contribution because modality translation replaces more resource-intensive processes and allows the model to learn directly from the data, rather than on a separate dataset. MARMOT is also able to process observations that are missing either images or text.
Applications
MARMOT was applied to two datasets. The first dataset contained tweets reporting election incidents during the 2016 U.S. general election, originally published in “Observing Election Incidents in the United States via Twitter: Does Who Observes Matter?” The tweets in this dataset report some kind of election incident. All of the tweets contain text, and about a third of them contain images. MARMOT performed better at classifying the tweets than the text-only classifier used in the original study.
In order to test MARMOT against a dataset containing images for every observation, the authors used the Hateful Memes dataset released by Facebook to assess whether a meme is hateful or not. In this case, a multimodal model is useful because it is possible for neither the text nor the image to be hateful, but the combination of the two may create a hateful message. In this application, MARMOT outperformed other multimodal classifiers in terms of accuracy.
Future Directions
As more and more political scientists use data from social media in their research, classifiers will have to become more sophisticated to capture all of the nuance and meaning that can be packed into small parcels of text and images. The authors plan to continue refining MARMOT, and expand the models to accommodate additional elements such as video, geographical information, and time of posting.